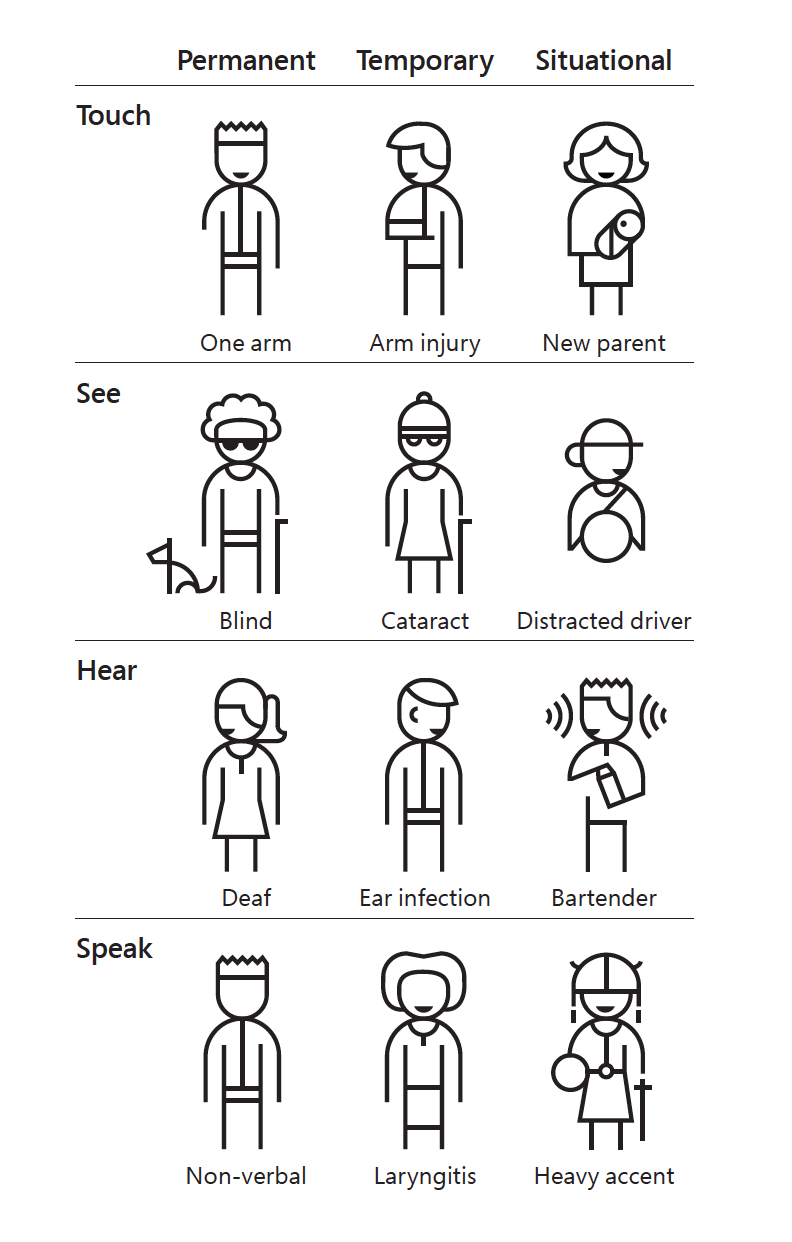
The topic I would like to focus on for this blog post centers around data justice and data accessibility to individuals that have disabilities and how our visualizations and presentation of data matter.
One of the key roles that data science plays is in the effective communication of data. Data visualizations are the main vehicle that allows data scientists to effectively convey findings and reach a broader audience. A data visualization is “the representation of data through use of common graphics” (IBM, n.d.). However, in order to promote equitable access to data and its findings it is important to consider that not all people are able to process data the same way. In the United States alone it is estimated that roughly twenty-five percent of the adult population has some sort of disability (Kahn 2023). Disabilities can range from cognitive, auditory, visual, and other levels of ability. Each of these disabilities can affect how someone is able to intake data and interpret data visualizations.
The following blog post aims to explore barriers for disabled persons to data access and actions data scientists can take in order to maintain data justice through accessible data access and scientific communication.
The main disabilities I will be exploring in the following sections are cognitive, and visual.
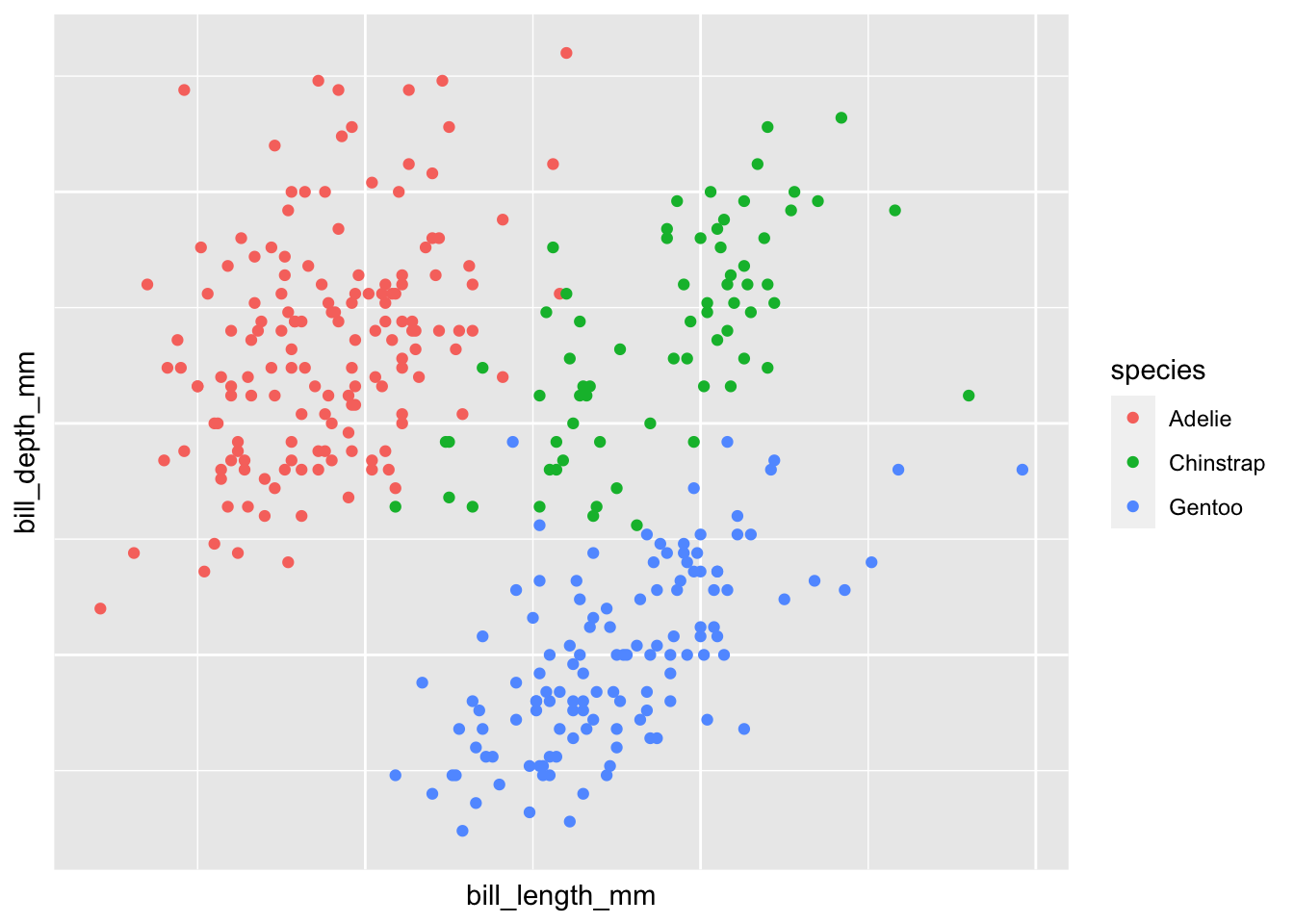
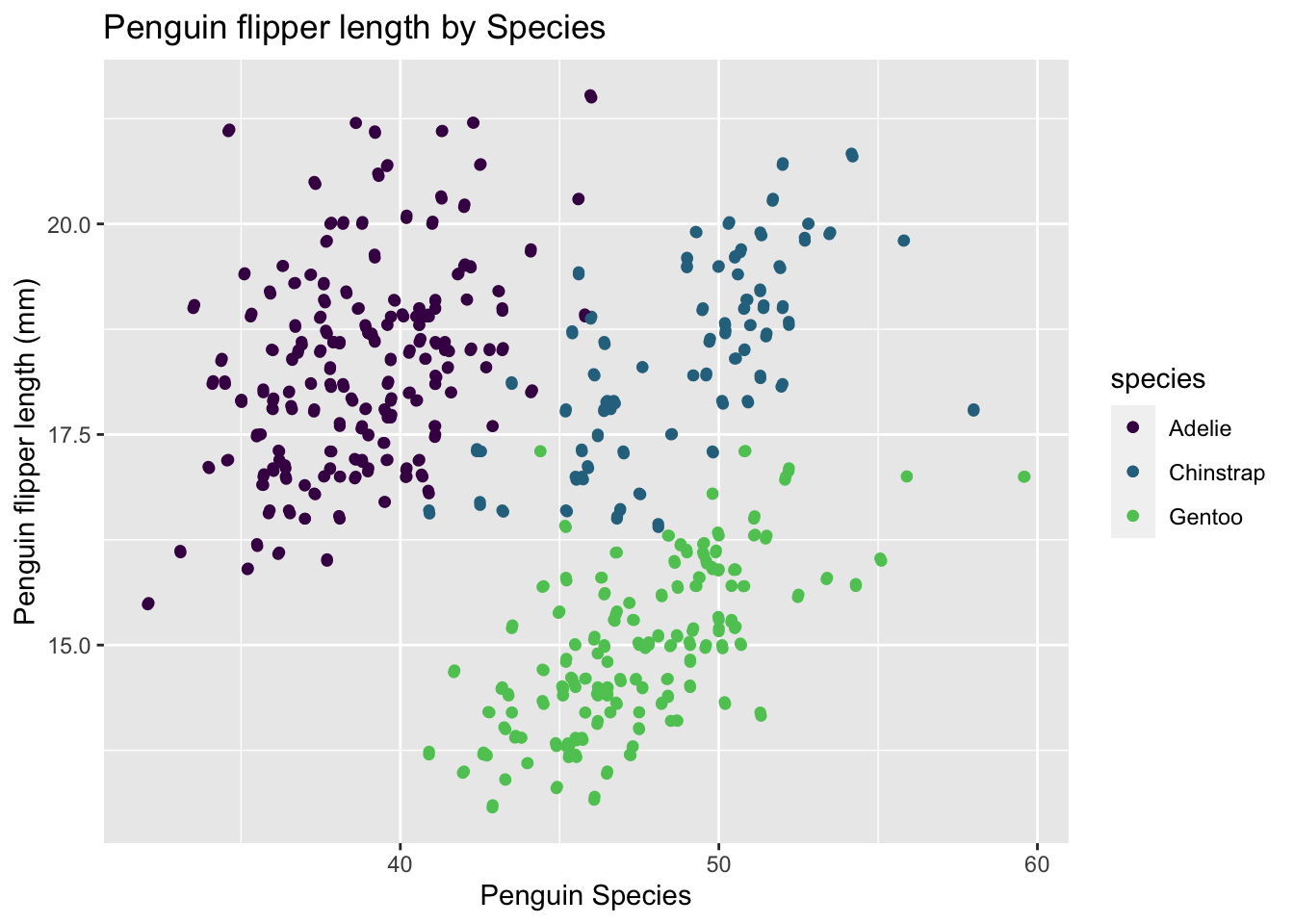
The following data visualization made from the PalmerPenguin package will be edited as well throughout this blog post highlighting tools mentioned to increase the accessibility of this visualization.
Cognitive disability, which can also be commonly referred to as Intellectual and Developmental Disabilities (IDD), has been a group of individuals often absent from the conversation around data accessibility. The following considerations and recommendation are from the research that has been conducted in the data visualization space for an audience that has IDD. Historically individuals with IDD have been pushed to the side of conversations regarding their own data as well as data around them that they would like to interact with. The main component of data visualization that data scientists consider when creating visualizations for those with cognitive disabilities or to be accessible to those with cognitive disabilities are how the data are presented. For cognitive disabilities when creating visualizations there are some specific considerations to keep in mind.
Data Design
Rethinking how we can present data to those with IDD is at the forefront of creating data that is more accessible for those with IDD. An emerging form of data science presentation is through the use of touch. Data scientists and artists are pairing up in order to create interactive displays and sculptures that present data. These data can be shown through the use of shapes, colors, and scaled sizing in an approachable format that prioritizes a major theme for each sculpture or installation(Corona 2019). Data presented in this way can allow individuals who might be unable to comprehend a visualization with many individual pieces the opportunity to interact with the data and understand the takeaway being shown.
An additional consideration when designing a data visualization is the type of figure that will be used. Research done at the University of Chapel Hill has revealed that pie charts are not accessible to those with IDD(Wu and Albers Szafir 2023). Thus, researchers and data scientists should consider if there are other visualizations that can be utilized.
Furthermore, something that data scientists should always consider is how to emphasize the main takeaway from their visualization. Data scientists should consider the level of visual complexity they are presenting and potentially isolate different takeaways with different figures. Clearly presenting the key finding of a figure can allow everybody to better understand a data visualization.
Data Visualization
When creating a data visualization and having the potential for an audience that has cognitive disabilities there are some design components that can be added or highlighted which will in general increase comprehension.
Labeling
Data scientists should ensure that labeling is intuitive, As an example, if data is being displayed regarding money, an easy to add label would be the $(Wu and Albers Szafir 2023).
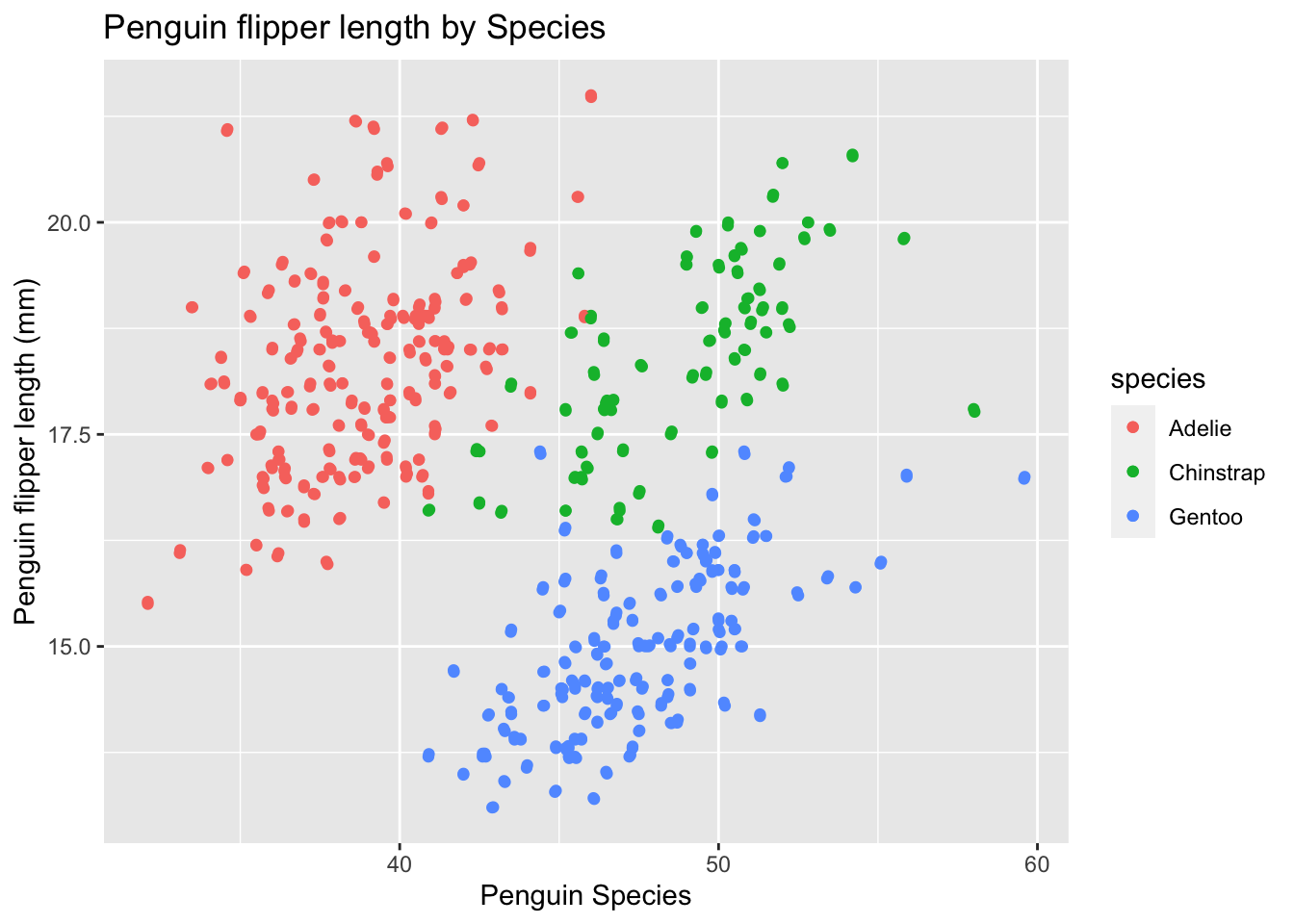
Axes
It is important to ensure that data presented in visualizations has clear start and end points(Wu and Albers Szafir 2023). Indication of where data is beginning and where data is ending on a visualization such as axes marks allows an audience member to definitively know where they should stop visually processing.
Code
axes <-ggplot(data = penguins, aes(x = bill_length_mm,y = bill_depth_mm, color = species)) +geom_point() +labs(x ="Penguin Species", y ="Penguin flipper length (mm)", title ="Penguin flipper length by Species") +geom_jitter()axes
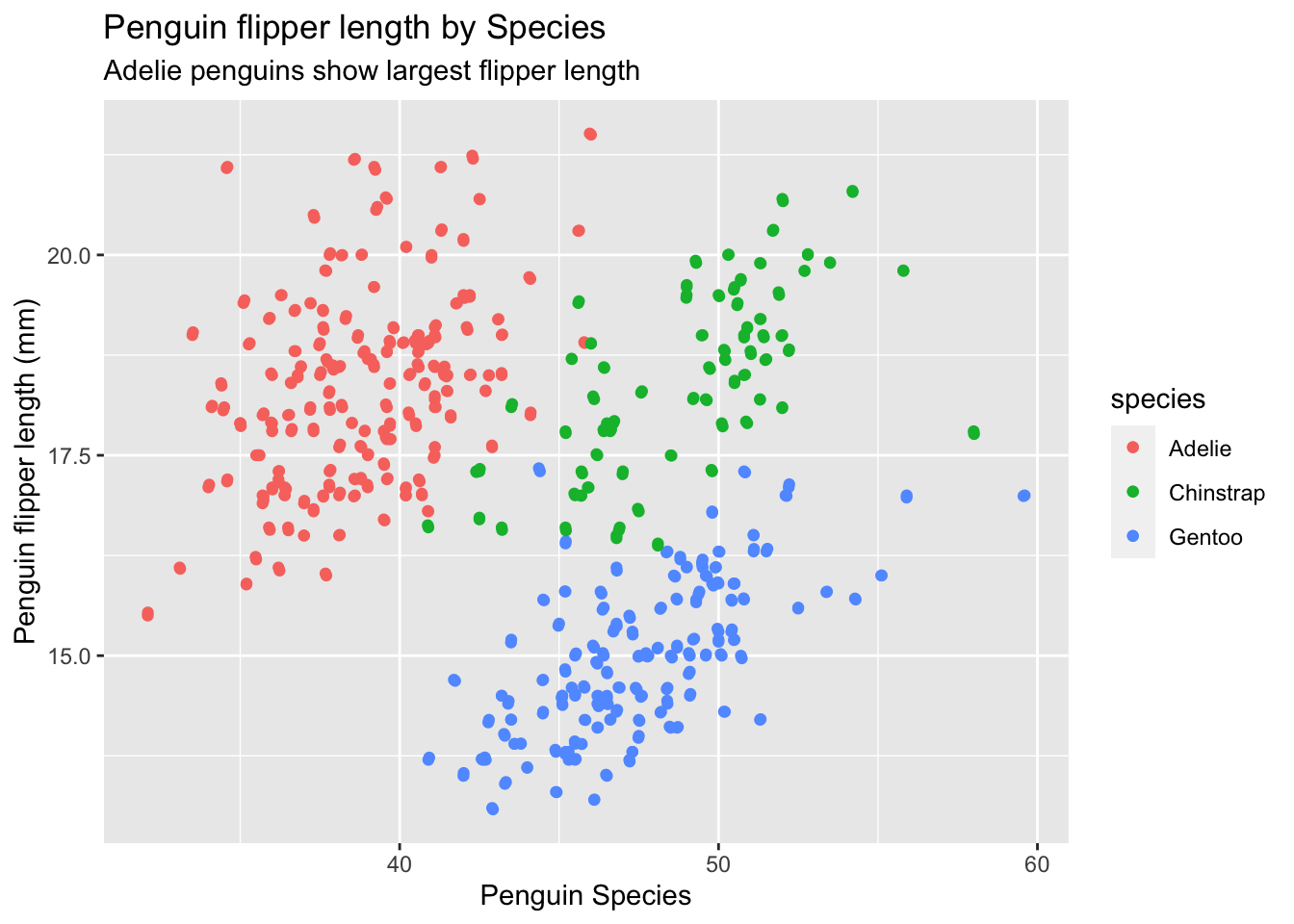
Titles
Informative titles can also be used to improve comprehension of a visualization(Knaflic Nussbaumer 2018). A title that includes the key takeaway from a visualization allows users to look for something in the data that supports the title which can increase comprehension.
Code
title <-ggplot(data = penguins, aes(x = bill_length_mm,y = bill_depth_mm, color = species)) +geom_point() +labs(x ="Penguin Species", y ="Penguin flipper length (mm)", title ="Penguin flipper length by Species", subtitle ="Adelie penguins show largest flipper length") +geom_jitter()title
Visual
Visual disability is a large and varied field. It is estimated that roughly eight percent of the U.S. population has blindness or a visual impairment that affects their daily life. Visual impairments is considered an umbrella term and is more concretely defined as vision that is unable to be corrected through the use of aids (glasses, or contacts) or surgery(Institute, n.d.). It is important to consider how data visualizations are created in order to maintain accessibility for users who have visual impairments.
Data Design
An emerging form of data representation is through the use of sounds. Sonified data uses non-speech sounds to explore and describe data. Data scientists can import data and create graphics through programs like the SAS Graphics Accelerator. The SAS Graphics accelerator enables scientists and the audiences they are trying to reach to access these data independently and create a framework they can succeed in.
Alternative Text
Data scientists can add alternative text (commonly referred to as Alt Text) to data visualizations. Alternative texts are often labeled with figure titles which provide very little information to someone who cannot clearly see the visualization. Alternative text should instead be thought of as a typed explanation of the figure. By providing more details in the alternative text adaptive technologies, like screen readers, can read the figure details to the user. Important things to include in the alt text would be the title, key trends, and a potential link to data in a readable format like a csv file(Nussbaumer Knaflic 2018). An additional consideration is that screen readers do not allow the user to alter or skip what is being read so it is important to ensure that the text you include is well thought out but a reasonable length.
Auditory Explanations
Figures and visualizations can also include a link or a sound-bite that walks a user through the figure. The use of auditory explanations allows users to see and explore data through the creators eyes as well as potentially receive a more-detailed explanation than the alternative text.
Data Visualization
Color
A potentially more common visual impairment is colorblindness. There are packages within R and Python that are specifically designed and built for people with color blindness(Ou 2021). Using colorblind-friendly color schemes is good practice to increase the accessibility of any chart or figure that is using color to differentiate data. Some examples of color-blind friendly palettes are the following:
friendly <-ggplot(data = penguins, aes(x = bill_length_mm,y = bill_depth_mm, color = species)) +geom_point() +labs(x ="Penguin Species", y ="Penguin flipper length (mm)", title ="Penguin flipper length by Species") +geom_jitter() +scale_color_viridis(discrete=TRUE, begin =0, end =0.75)friendly
High contrast elements
High contrast elements also allow for increased readability for those with visual impairments(nussbaumerknaflic2018?). The contrast between colors of elements and the sizes of these elements can affect the visual ease of use for users. There are multiple tools that data scientists can utilize to check the contrast of their images and even design a palette they would like to use.
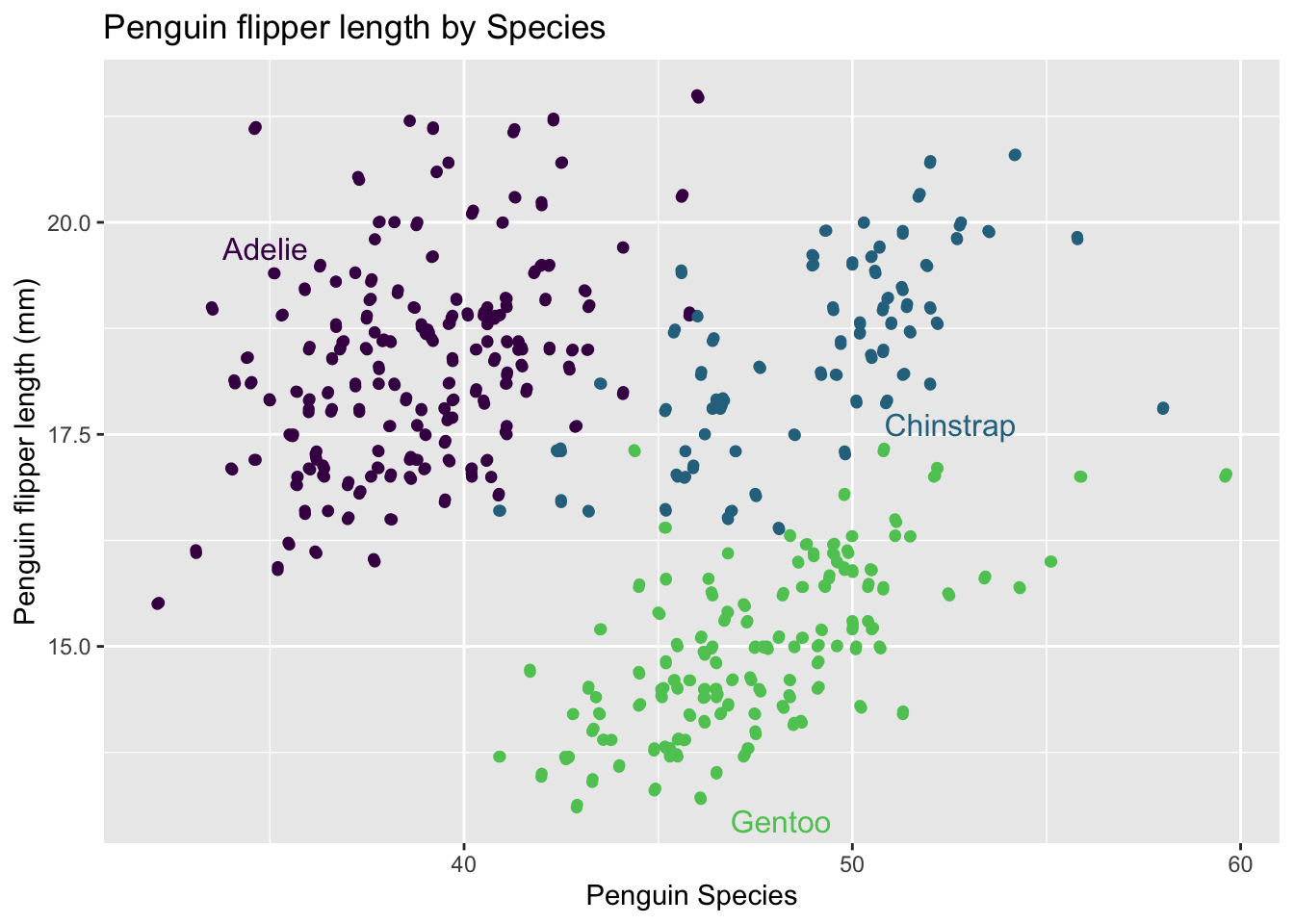
Labeling Data
A barrier to users with low vision can be legends(nussbaumerknaflic2018?). Legends can typically include smaller text that is positioned outside of where the bulk of data is shown through the figure. This can create a disconnect between the data shown and any qualifiers assigned to it like scale, or type. A possible solution for this is direct labeling. Direct labeling can be labels next to data or within the data visualization. A package that can be used is the directlabels package.
Code
label <-ggplot(data = penguins, aes(x = bill_length_mm,y = bill_depth_mm, color = species)) +geom_point() +labs(x ="Penguin Species", y ="Penguin flipper length (mm)", title ="Penguin flipper length by Species") +geom_jitter() +scale_color_viridis(discrete=TRUE, begin=0, end =0.75) +theme(legend.position="none") label2 <-direct.label(label, method =NULL, debug =FALSE) label2
Environmental Data
As the field of data science continues to grow and be at the forefront of scientific communication, especially environmental scientific communication, we as data scientists need to keep in mind how our visualizations and findings are received. Environmental analyses, and visualizations are some of the most impactful tools scientists have to educate the public on environmental challenges. In order to create the most cutting edge solutions that prioritize people and the environment around us, we as data scientists need to ensure people of all backgrounds are at the table making decisions. Everyone, regardless of their ability, have the right to access data and what we can learn from it.
Takeaway
We have covered numerous strategies in order to make data visualizations more accessible. Now depending on the goal of a researcher doing every one of these strategies could be an impossible task considering timelines and budgets. However, it is important for data scientists to think critically about who their audience is and if some of the strategies discussed can be applied. Some additions and considerations like, incorporating alternative text that is clear and concise and high contrast color palettes take minimal time and are often pre-built into some packages. Data scientists of all backgrounds, including within the environmental realm have the responsibility to consider how their data visualizations are able to be received and by what audiences.
Wu, Keke, and Danielle Albers Szafir. 2023. “Empowering People with Intellectual and Developmental Disabilities Through Cognitively Accessible Visualizations,” September. https://doi.org/https://doi.org/10.48550/arXiv.2309.12194.
Citation
BibTeX citation:
@online{widas2023,
author = {Widas, Melissa},
title = {Data {Visualization} {Accessibility}},
date = {2023-11-26},
url = {https://mwidas.github.io/blog-posts/2023-11-26-data-accessibility/},
langid = {en}
}